本资料来自 Workday 的软件开发工程师 Jianneng Li 在 Spark Summit North America 2020 的 《On Improving Broadcast Joins in Spark SQL》议题的分享。背景相信使用 Apache Spark 进行数据分析的同学对 Spark 中的 Broadcast Join 比较熟悉,其在 Join 之前会把一端比较小的表广播到参与 Join 的 worker 端,具体如下:如果想及时了解Spark、Hadoop或者HBase相关的文 w397090770 4年前 (2020-07-05) 2065℃ 0评论4喜欢
由于Spark基于内存计算的特性,集群的任何资源都可以成为Spark程序的瓶颈:CPU,网络带宽,或者内存。通常,如果内存容得下数据,瓶颈会是网络带宽。不过有时你同样需要做些优化,例如将RDD以序列化到磁盘,来降低内存占用。这个教程会涵盖两个主要话题:数据序列化,它对网络性能尤其重要并可以减少内存使用,以及内存调优 w397090770 6年前 (2019-02-20) 3198℃ 0评论8喜欢
Spark的其中一个目标就是使得大数据应用程序的编写更简单。Spark的Scala和Python的API接口很简洁;但由于Java缺少函数表达式(function expressions), 使得Java API有些冗长。Java 8里面增加了lambda表达式,Spark开发者们更新了Spark的API来支持Java8的lambda表达式,而且与旧版本的Java保持兼容。这些支持将会在Spark 1.0可用。如果想及时了解 w397090770 10年前 (2014-07-10) 13193℃ 0评论18喜欢
Shanghai Apache Spark Meetup第十次聚会活动将于2016年09月10日12:30 至 17:20在四星级的上海通茂大酒店 (浦东新区陆家嘴金融区松林路357号)。分享主题1、中国电信在大数据领域上的创新与探索2、函数式编程与RDD3、社交网络中的信息传播4、大数据分析和机器学习5、分布式流式数据处理框架:功能对比以及性能评估详细主 zz~~ 8年前 (2016-09-20) 1793℃ 0评论2喜欢
Hadoop 社区推出了新一代分布式Key-value对象存储系统 Ozone,同时提供对象和文件访问的接口,从构架上解决了长久以来困扰HDFS的小文件问题。本文作为Ozone系列文章的第一篇,抛个砖,介绍Ozone的产生背景,主要架构和功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop背景HDFS是业界默认的 w397090770 4年前 (2020-05-26) 1905℃ 1评论1喜欢
在MapReduce作业中的数据输入和输出必须使用到相关的InputFormat和OutputFormat类,来指定输入数据的格式,InputFormat类的功能是为map任务分割输入的数据。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop InputFormat类中必须指定Map输入参数Key和Value的数据类型,以及对输入的数据如何进行分 w397090770 9年前 (2015-07-11) 5506℃ 0评论14喜欢
Avro(读音类似于[ævrə])是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting牵头开发。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。 在Hive中,我们可以将数据 w397090770 11年前 (2014-04-08) 15806℃ 1评论6喜欢
在很多应用场景都需要对结果数据进行排序,Spark中有时也不例外。在Spark中存在两种对RDD进行排序的函数,分别是 sortBy和sortByKey函数。sortBy是对标准的RDD进行排序,它是从Spark 0.9.0之后才引入的(可以参见SPARK-1063)。而sortByKey函数是对PairRDD进行排序,也就是有Key和Value的RDD。下面将分别对这两个函数的实现以及使用进行说明。 w397090770 10年前 (2014-12-26) 83764℃ 7评论91喜欢
微信公众号开发者模式可以支持自动回复回复文本、图片、图文、语音、视频以及音乐(参见 被动回复用户消息),下面是回复图片消息的返回结果格式:[code lang="xml"]<xml> <ToUserName><![CDATA[toUser]]></ToUserName> <FromUserName><![CDATA[fromUser]]></FromUserName> <CreateTime>12345678</CreateTime> <MsgType> w397090770 4年前 (2020-08-04) 760℃ 0评论1喜欢
里氏替换法则(Liskov Substitution Principle LSP)是面向对象设计的六大基本原则之一(单一职责原则、里氏替换原则、依赖倒置原则、接口隔离原则、迪米特法则以及开闭原则)。这里说说里氏替换法则:父类的一个方法返回值是一个类型T,子类相同方法(重载或重写)返回值为S,那么里氏替换法则就要求S必须小于等于T,也就是说要么 w397090770 11年前 (2013-09-12) 4262℃ 3评论0喜欢
在本博客的《Apache Kafka-0.8.1.1源码编译》文章中简单地谈到如何用gradlew或sbt编译Kafka 0.8.1.1的代码。今天主要来谈谈如何部署一个分布式集群。以下本文所有的内容都是基于Kafka 0.8.1.1(Kafka 0.7.x的操作命令和本文略有不同,请注意!)在介绍Kafka分布式部署之前,先来了解一下Kafka的基本概念。 (1)Kafka维护按类区分的消息 w397090770 10年前 (2014-06-23) 19046℃ 0评论20喜欢
Apache Kafka 近期发布了 2.3.0 版本,主要的新特性如下:Kafka Connect REST API 已经有了一些改进。Kafka Connect 现在支持增量协同重新均衡(incremental cooperative rebalancing)Kafka Streams 现在支持内存会话存储和窗口存储;AdminClient 现在允许用户确定他们有权对主题执行哪些操作;broker 增加了一个新的启动时间指标;JMXTool现在可以连接到安 w397090770 5年前 (2019-06-27) 3053℃ 0评论6喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 北京第五次Spark meetup会议 w397090770 10年前 (2015-01-31) 3737℃ 0评论4喜欢
金山云-企业云团队(赵侃、李金辉)在交互查询场景下对Presto与Alluxio相结合进行了一系列测试,并总结了一些Presto搭配Alluxio使用的建议。本次测试未使用对象存储,计算引擎与存储间的网络延时也比较低。如果存储IO耗时和网络耗时较大时,Alluxio加速收益应会更明显。测试目的验证影响Alluxio加速收益的各种因素记录Alluxio w397090770 3年前 (2022-03-29) 778℃ 0评论2喜欢
我们在《Tachyon 0.7.0伪分布式集群安装与测试》文章中介绍了如何搭建伪分布式Tachyon集群。从官方文档得知,Spark 1.4.x和Tachyon 0.6.4版本兼容,而最新版的Tachyon 0.7.1和Spark 1.5.x兼容,目前最新版的Spark为1.4.1,所以下面的操作步骤全部是基于Tachyon 0.6.4平台的,Tachyon 0.6.4的搭建步骤和Tachyon 0.7.0类似。 废话不多说,开始介绍吧 w397090770 9年前 (2015-08-31) 5473℃ 0评论6喜欢
VSFTP是一个基于GPL发布的类Unix系统上使用的FTP服务器软件,它的全称是Very Secure FTP 从此名称可以看出来,编制者的初衷是代码的安全。本文将介绍如何在CentOS系统上安装、部署和卸载vsftp。1. 安装VSFTP[code lang="bash"][iteblog@www.iteblog.com ~]# yum -y install vsftpd[/code]2. 配置vsftpd.conf文件[code lang="bash"][iteblog@www.iteblog.com ~]# v w397090770 9年前 (2016-04-16) 2100℃ 0评论3喜欢
本文作者:王祥虎,原文链接:https://mp.weixin.qq.com/s/LvKaj5ytk6imEU5Dc1Sr5Q,欢迎关注 Apache Hudi 技术社区公众号:ApacheHudi。Apache Hudi是由Uber开发并开源的数据湖框架,它于2019年1月进入Apache孵化器孵化,次年5月份顺利毕业晋升为Apache顶级项目。是当前最为热门的数据湖框架之一。如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢 w397090770 4年前 (2020-10-09) 1841℃ 0评论2喜欢
过去十年,存储的速度从 50MB/s(HDD)提升到 16GB/s(NvMe);网络的速度从 1Gbps 提升到 100Gbps;但是 CPU 的主频从 2010 年的 3GHz 到现在基本不变,CPU 主频是目前数据分析的重要瓶颈。为了解决这个问题,越来越多的向量化执行引擎被开发出来。比如数砖的 Photon 、ClickHouse、Apache Doris、Intel 的 Gazelle 以及 Facebook 的 Velox(参见 《Velox 介绍 w397090770 2年前 (2022-09-29) 1920℃ 0评论3喜欢
背景 B站的YARN以社区的2.8.4分支构建,采用CapacityScheduler作为调度器, 期间进行过多次核心功能改造,目前支撑了B站的离线业务、实时业务以及部分AI训练任务。2020年以来,随着B站业务规模的迅速增长,集群总规模达到8k左右,其中单集群规模已经达到4k+ ,日均Application(下文简称App)数量在20w到30w左右。当前最大单集群整体cpu w397090770 2年前 (2022-04-11) 788℃ 0评论2喜欢
[caption id="attachment_751" align="aligncenter" width="536"] Guava学习之SetMultimap[/caption] SetMultimap及其子类的继承图如上所示。 SetMultimap是一个接口,继承自Multimap接口,同昨天说的ListMultimap接口类似,它也定义了所有继实现自SetMultimap的子类定义了一些共有的方法签名。SetMultimap接口并没有定义自己特有的方法签名,里面所 w397090770 11年前 (2013-09-25) 9207℃ 1评论4喜欢
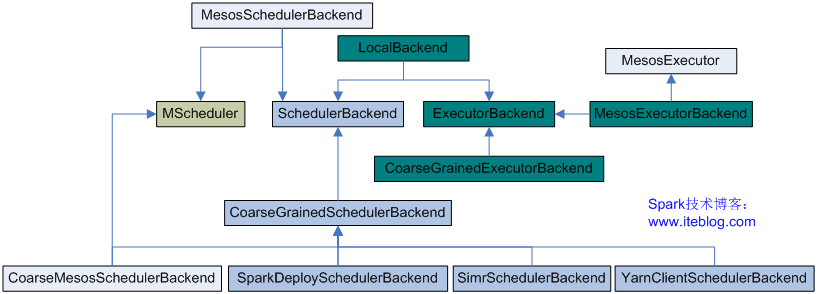
《Spark源码分析:多种部署方式之间的区别与联系(1)》《Spark源码分析:多种部署方式之间的区别与联系(2)》 在《Spark源码分析:多种部署方式之间的区别与联系(1)》我们谈到了SparkContext的初始化过程会做好几件事情(这里就不再列出,可以去《Spark源码分析:多种部署方式之间的区别与联系(1)》查看),其中做了一件重要 w397090770 10年前 (2014-10-28) 7689℃ 6评论8喜欢
Shanghai Apache Spark Meetup第十一次聚会,将于12月10日,举办于上海大连路688号宝地广场22楼小沃科技活动场地。靠近地铁4号线和12号线的大连路站。本次会议得到中国联通小沃科技的大力支持。欢迎大家前来参加!会议主题1、演讲主题:《Spark Streaming构建实时系统介绍》 演讲嘉宾:程然,小沃科技高级架构师,开源爱好者 w397090770 8年前 (2016-12-01) 1837℃ 0评论5喜欢
尽量不要把数据 collect 到 Driver 端如果你的 RDD/DataFrame 非常大,drive 端的内存无法放下所有的数据时,千万别这么做[code lang="scala"]data = df.collect()[/code]Collect 函数会尝试将 RDD/DataFrame 中所有的数据复制到 driver 端,这时候肯定会导致 driver 端的内存溢出,然后进程出现 crash。如果想及时了解Spark、Hadoop或者HBase相关的文章, w397090770 4年前 (2020-06-23) 749℃ 0评论3喜欢
Thrift 最初由Facebook开发,目前已经开源到Apache,已广泛应用于业界。Thrift 正如其官方主页介绍的,“是一种可扩展、跨语言的服务开发框架”。简而言之,它主要用于各个服务之间的RPC通信,其服务端和客户端可以用不同的语言来开发。只需要依照IDL(Interface Description Language)定义一次接口,Thrift工具就能自动生成 C++, Java, Python, PH w397090770 8年前 (2016-06-30) 3698℃ 0评论7喜欢
本书于2017-07由Packt Publishing出版,作者Christopher Bourez,全书440页。关注大数据猿(bigdata_ai)公众号及时获取最新大数据相关电子书、资讯等通过本书你将学到以下知识Get familiar with Theano and deep learningProvide examples in supervised, unsupervised, generative, or reinforcement learning.Discover the main principles for designing efficient deep learning nets: convolut zz~~ 7年前 (2017-08-23) 2384℃ 0评论8喜欢
在高德纳的计算机程序设计艺术中,有如下问题:可否在一未知大小的集合中,随机取出一元素?。或者是Google面试题: I have a linked list of numbers of length N. N is very large and I don’t know in advance the exact value of N. How can I most efficiently write a function that will return k completely random numbers from the list(中文简化的意思就是:在不知道文件总行 w397090770 9年前 (2015-11-09) 10260℃ 0评论16喜欢
《Apache Kafka监控之Kafka Web Console》《Apache Kafka监控之KafkaOffsetMonitor》《雅虎开源的Kafka集群管理器(Kafka Manager)》Kafka在雅虎内部被很多团队使用,媒体团队用它做实时分析流水线,可以处理高达20Gbps(压缩数据)的峰值带宽。为了简化开发者和服务工程师维护Kafka集群的工作,构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka M w397090770 10年前 (2015-02-04) 22088℃ 0评论14喜欢
Data + AI Summit 2022 于2022年06月27日至30日举行。本次会议是在旧金山进行,中国的小伙伴是可以在线收听的,一共为期四天,第一天是培训,后面几天才是正式会议。本次会议有超过200个议题,演讲嘉宾包括业界、研究和学术界的专家,本次会议主要分为六大块:数据分析, BI 以及可视化:了解最新的数据分析、BI 和可视化技术以及 w397090770 2年前 (2022-07-10) 607℃ 0评论3喜欢
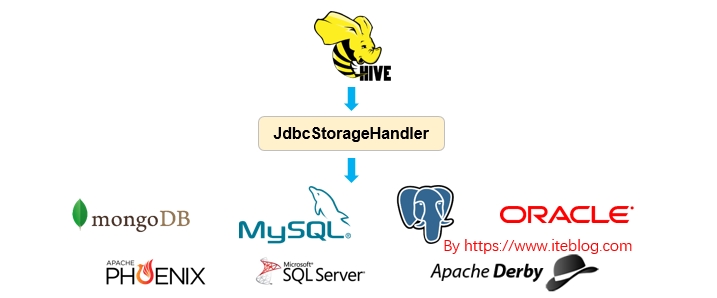
如今,很多公司可能会在内部使用多种数据存储和处理系统。这些不同的系统解决了对应的使用案例。除了传统的 RDBMS (比如 Oracle DB,Teradata或PostgreSQL) 之外,我们还会使用 Apache Kafka 来获取流和事件数据。使用 Apache Druid 处理实时系列数据(real-time series data),使用 Apache Phoenix 进行快速索引查找。 此外,我们还可能使用云存储 w397090770 6年前 (2019-03-16) 5146℃ 1评论8喜欢
Marius Eriksen, Twitter Inc. marius@twitter.com (@marius) [translated by hongjiang(@hongjiang), tongqing(@tongqing)]序言 Scala是Twitter使用的主要应用编程语言之一。很多我们的基础架构都是用scala写的,我们也有一些大的库支持我们使用。虽然非常有效, Scala也是一门大的语言,经验教会我们在实践中要非常小心。 它有什么陷阱?哪些特 w397090770 10年前 (2015-04-11) 7430℃ 0评论3喜欢















![[电子书]Deep Learning with Theano PDF下载](https://www.iteblog.com/pic/books/Deep_Learning_with_Theano_iteblog.png)